Introduction
Like many other companies, we have a Data Warehouse that brings together all our production data sources into a single location to enable various business functions such as business intelligence, data analytics, experiment analysis etc.
For a long time, we have done this by copying our production postgres tables using a batch ETL process (we have in house scripts running on a scheduler to do the copies every 'n' hours) without any transformations. Consumers of the data warehouse, in turn, have used these tables to perform all of the operations listed above.
The Problem
While this process has served us well, as we have moved to modernize our technology stack, this approach has started to show some limitations:
- One of the guiding principles of good software design is
strong module boundaries
which allows one business domain to be designed and evolve independently of other domains. The systems
within these domains interact with each other over contracts at the http layer, not the data layer.
By copying data maintained by these systems verbatim to the data warehouse (which represents a boundary),
we end up crossing these boundaries leading to the inadvertant coupling of these production and
data warehouse systems. This issue manifests itself in many areas:
- Any migrations on the table or changes in the logic of the fields stored in the tables are blocked by the fact that these changes need to be propagated to the data warehouse and all consumers of these tables need to migrate their processes to account for them before they can be released to our end users.
- Non product concerns (whether an entity was created from the mobile or desktop site, for example) leak into the production data models since these tables are, in turn, used for BI and related processes.
- As an engineering team, we're starting to adopt high scalability/availability data stores (DynamoDB) or versatile data stores (MongoDB, Cloudsearch). Since our ETL jobs can only use SQL interfaces (postgres), the data from these stores needs to be moved to a compatible data store, which usually means that the schema exposed won't be a verbatim copy of the production data models in these cases.
- Because we copy the production data models directly into the data warehouse, we lack a consistent schema that consumers of the data warehouse can use, suggest improvements for, ask questions of etc. The choices of each product team, instead, are exposed to these consumers leading to difficulities in understanding the data exposed via each table (inconsistent column names and types, difficulties in understanding how to join tables, etc.). Furthermore, as we move more of our domains to be built as finer grained services, we naturally end up denormalizing the data, spreading it across multiple tables maintained by different services. This leads to confusion in the data warehouse since it's hard to know which table should be used as the trusted source for any given piece of data.
Again, this process has worked well for us, especially when we had a monolithic system with a few handful of databases and tables. However, as we continue to scale in usage of the data warehouse, in our technology as well as organizationally, our understanding of the drawbacks of the existing system as well as the best practices involved in operating a data warehouse have evolved.
An example of the drawbacks manifesting themselves came about earlier this year when we were wrapping up a rather big modernization project. Modernization, for us, is not simply a rewrite from our legacy (Perl) stack to our new (JVM based) stack but a complete rethinking of the bounded context (BC) we're working on. As such, this project involved, among other things, a complete rethinking of the data model of BC in question (I'll write more about this process, the choices we made, the difficulties we faced as well as the mistakes we made in a later post). Since this was an existing BC, we already had a lot of internal processes spread across disparate teams (marketing, analytics, product, customer support, data science and more) using the data from the existing data model. And since we used to expose the raw tables from our legacy data model to these users, all their work was tied directly to this one table. Because of this, when the time came to switch to the new data model, we not only had to work with multiple teams to update their scripts but also had to ensure that the new processes they write are not directly tied to the new tables in our production system we had built.
Solution - Purgatory
To solve the issues described above, we introduced and enforced boundaries between the data flows in our ETL jobs as well as hand offs at various steps in these flows. The new workflow is described in the diagram below.
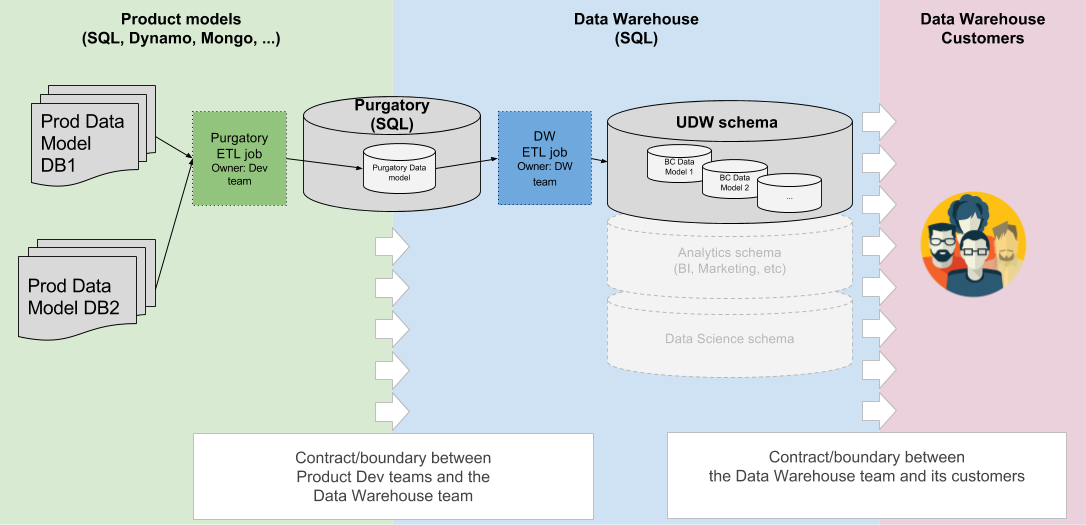
The diagram above describes a product data model for the given BC (spread across multiple databases and multiple tables within each DB). This process requires that each development team of any given BC (and services within) will be responsible for creating, running and maintaining an ETL job that feeds a view of their data in purgatory. The only consumer of this data will be the data warehouse ETL job (and the team that owns it) which will, in turn, be responsible for extracting this data and exposing it to their consumers in a schema that is consistent over time and where the data is reconciled at regular intervals.
The introduction of purgatory allows:
- Product models to evolve independently from the data warehouse schema. The contract the product team exposes in purgatory requires them to ensure that any changes are backwards compatible (just as they do with their http contracts). In addition, any changes to the contract exposed via purgatory only needs to be coordinated with the data warehouse team and their ETL job as opposed to the entire data warehouse community of users.
- Separation of concerns for the product teams and the services they are building. These efforts can be focused on building (testing, releasing, A/B testing etc.) the product as well as maintaining the contracts with other product consumers (including purgatory) without having to focus on the impact of the changes to the data warehouse consumers (marketing, analytics, product, finance, trust & safety etc. - all of whom have different requirements).
- Consistent ETL pipelines that various teams can reuse to expose data in purgatory.
- A single location to vet and reconcile our data before exposting it to users of the data warehouse.
- Allows us to define a consistent schema for UDW consumers
- In the future, this process will also allow us to define multiple schemas and dimensions specific to the questions being asked within the data warehouse
Implementation and Results
We ended up creating the purgatory ETL jobs using AWS Data Pipeline (a subject for another blog post) and delivering the data to the data warehouse ETL jobs in an RDS Postgres database. The second ETL job only cares about the one table we expose to the data warehouse team where the data is combined from the disparate databases and tables the production services use.
This process has been running for the last 6 months at this point, and has been adopted by many other teams and projects internally to do the same. The outcome of this has, so far, been encouraging. One of the vertical teams, for example, was building an MVP of a product to see it's market viability. For such projects, time to market is a big concern, and so, we ended up using postgres as a key value store (values being a serialized thrift entity stored in a jsonb column) to launch as soon as we could. While this worked very well for the product, it would not have worked well for the data warehouse since querying a jsonb column isn't exactly easy. Instead of making a simple copy of the table(s) in question, we copied our existing AWS data pipeline jobs, made modifications to the transformation scripts, agreed with the data warehouse team on a set of contracts (tables) we'd deliver to them and let them work on transforming the data from these tables into the final versions exposed in the data warehouse to be used by the analytics and product teams to understand the efficacy of the new solution we'd launched.