Let's talk a little bit about EMR Spark Steps.
This is the recommended way to kick off spark jobs in EMR. Well, recommended at-least for streaming jobs (since that's all
I have experience with so far).
When running a spark job in standalone mode, you usually end up doing so by using spark-submit after downloading your
spark distribution.
That command usually ends up looking something like this (the parameters passed in are not important for now):
bin/spark-submit --packages org.apache.spark:spark-streaming-kinesis-asl_2.11:2.2.0 ~/spark/job.py stream
The EMR step does something very similar. Only differnece (for me, anyways) is that I don't need to ssh into the master node
and kick the job off manually. In addition, by doing so, you get to see your steps and their status in the EMR cluster's dashboard
on the AWS UI.
Now, here's what starting the cluster via the AWS UI would look like:
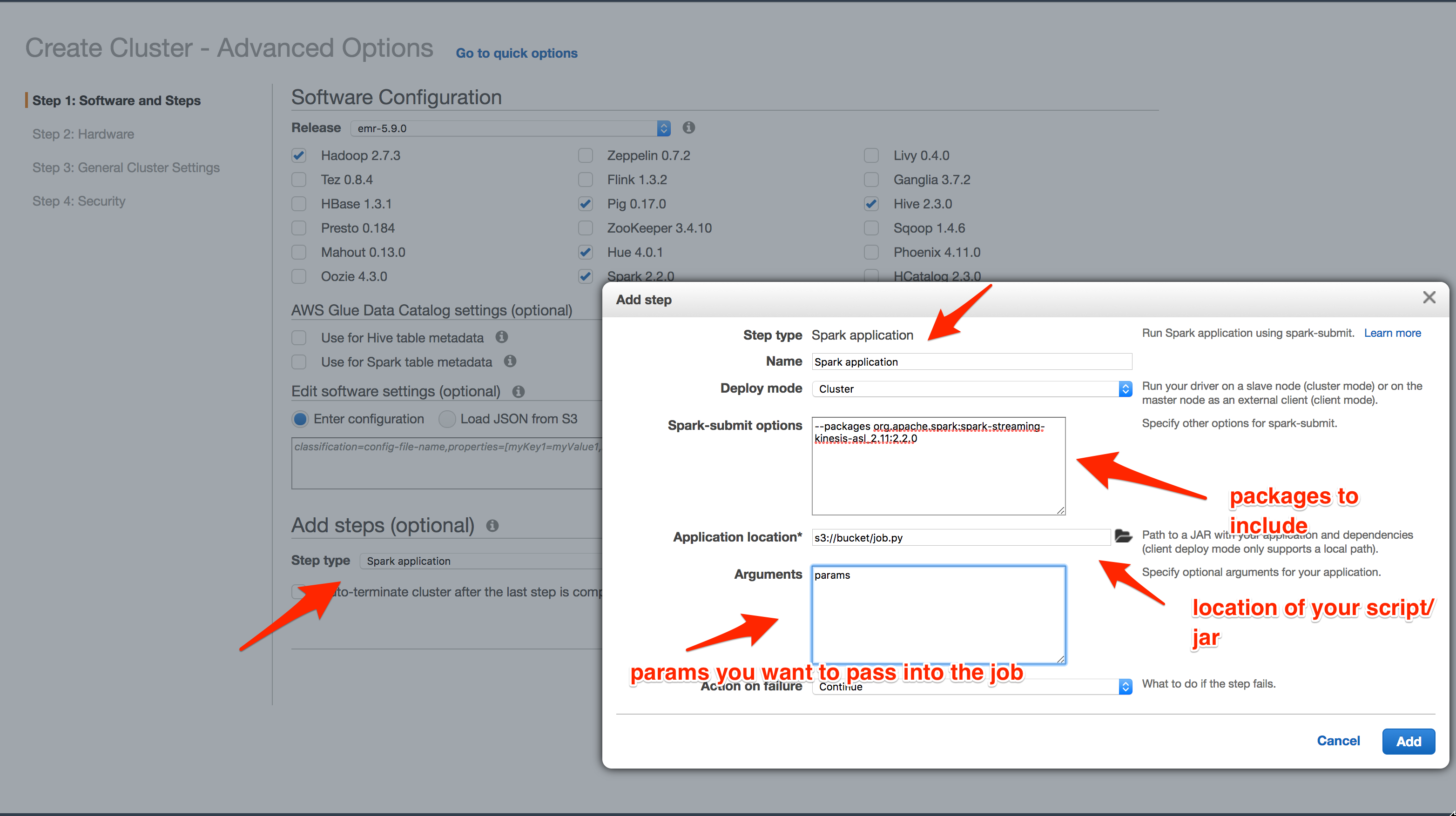
The steps I followed to get this to work as I expected it to:
- On the Create Cluster screen, click on "Go to advanced options" at the top (there's a link next to the Quick Options text)
- Once you are on the Advanced Options screen, you can select the EMR version as well as the applications you want your cluster to have.
One of these has to be Spark, since we're starting a spark streaming app.
- Now, under the Add Steps section, you want to select the Spark Application step type and click configure.
- In the dialog that opens next, we start filling in the various options shown in the screenshot above
- You can give your step a name. I haven't ever changed the default so far, since I'm only running a single job on the cluster for now.
- I haven't ever changed the deploy mode either. The help instructions there give you some info, so feel free to give it a shot :)
- Now comes the interesting bits. Spark-submit options are the options you'd want to pass in to the spark-submit command.
This is where you'd pass in, for example, the kinesis streaming jar (since it doesn't come pre-packaged with spark) as I've
done in the screenshot above.
- Application location is where you've put your jar or python script that you'd want spark to execute. As is usual with many AWS
services, they want this to be in S3.
- Arguments are the parameters you want to pass in to your streaming application. Usually, this would include the stream name you want to
target or the environment this job is running in etc (I haven't figured out how to set the environment as a system variable on each node in
the cluster).
- Finally, the Action on Failure option let's you specify what you want to have happen with the cluster when the step fails. The options
I have tried out are Terminate and Continue both of which do what you'd expect them to do (i.e. the former shuts down the EMR cluster
and the latter keeps it running).
You can of-course, do all this via the CLI as well. The command to do this looks like:
aws emr create-cluster --termination-protected --applications Name=Hadoop Name=Zeppelin Name=Spark Name=Ganglia --release-label emr-5.9.0 --steps '[{"Args":["spark-submit","--deploy-mode","cluster","--packages","org.apache.spark:spark-streaming-kinesis-asl_2.11:2.2.0","s3://bucket/job.py","params1", "params2"],"Type":"CUSTOM_JAR","ActionOnFailure":"CONTINUE","Jar":"command-runner.jar","Properties":"","Name":"Spark application"}]' --instance-groups '[{"InstanceCount":1,"InstanceGroupType":"MASTER","InstanceType":"m3.xlarge","Name":"Master - 1"},{"InstanceCount":2,"InstanceGroupType":"CORE","InstanceType":"m3.xlarge","Name":"Core - 2"}]' --auto-scaling-role EMR_AutoScaling_DefaultRole --ebs-root-volume-size 10 --service-role EMR_DefaultRole --enable-debugging --name 'RMSparkCluster' --scale-down-behavior TERMINATE_AT_INSTANCE_HOUR --region us-west-2
The only interesting part about this is how to pass in the options to the --steps parameter. You do this with individual strings in the list you pass in; not sure why this is.
That's it - with this, you now have specific an EMR Spark Step that'll let you run your streaming job when your EMR cluster comes up. I've found
that use Spark Steps makes it much easier to kick off Spark streaming jobs against a kinesis stream along and have things like metrics, status and the
number of jobs running.